
LLM Engineering 101: Mastering the Modern AI Stack

In the world of 2026, "generative AI" has evolved from a novelty into a rigorous engineering discipline. Whether you are building an autonomous agent or a simple summarizer, success lies in understanding the three layers of LLM engineering and knowing when to use a Frontier model versus an Open Source one.
The Building Blocks: A Three-Dimensional View
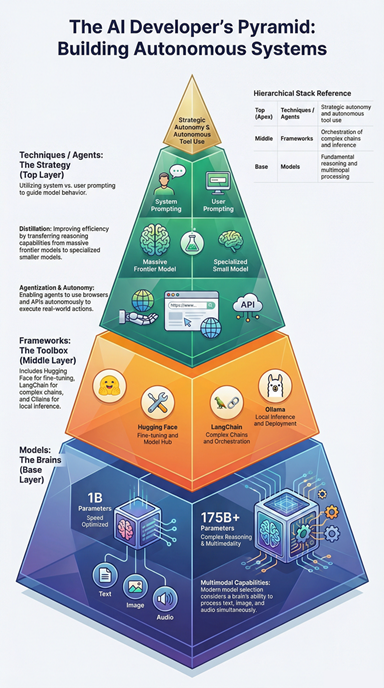
To build commercial-grade AI, you must navigate three distinct factors. Think of this as the "AI Developer's Pyramid."
Layer 1: The Models (The Brains)
At the base, we have the models themselves. In 2026, this isn’t just text. We now work with Multimodal models—brains that "see" images and "hear" audio natively. Engineering at this layer involves Model Selection: choosing a $1B$ parameter model for speed or a $175B+$ model for complex reasoning.
Layer 2: The Frameworks (The Toolbox)
The "glue" that connects models to your data.
Hugging Face: The library for downloading and fine-tuning open-source models.
LangChain / LangGraph: For building complex chains and agentic loops.
Ollama: The industry standard for running local inference with a single command.
Layer 3: The Techniques (The Strategy)
This is where the "Engineering" happens. It includes:
Prompting: Using System vs. User prompts to guide behavior.
Distillation: Using a massive model (like GPT-5) to teach a tiny model (like Llama 4 Scout) how to perform a specific task.
Agentization: Giving models the power to use tools—like a terminal, a browser, or your company's API—to complete goals autonomously.
The Great Divide: Frontier vs. Open Source
In 2026, the gap between "private" and "public" models has narrowed, but the choice still defines your project’s cost and privacy.
The Frontier (Closed Source)
These are the heavyweights. They are massive, expensive to run, and accessible only via API.
Claude 4.5 Sonnet: The current champion for "Agentic Coding" (SWE-bench).
GPT-5: The gold standard for general-purpose reasoning and reliability.
Gemini 2.5 Pro: Famous for its "infinite" context window (up to 10M tokens).
The Open Source (Open Weights)
You can download these and run them on your own hardware.
Llama 4 (Meta): The most popular open-source family, now featuring "Mixture of Experts" architecture for efficiency.
DeepSeek-V3.2: The efficiency king. DeepSeek proved that high-level reasoning doesn't require a $100M training budget.
gpt-oss-120b: OpenAI's first massive open-source model, designed to compete directly with their own GPT-4 level intelligence.
| Feature | Frontier (Closed) | Open Source (Open Weights) |
| Privacy | Data sent to the provider | 100% On-Premise |
| Setup | API Key (Easy) | GPU/Server Needed (Complex) |
| Cost | Pay-per-token | Free (after hardware cost) |
Inference: Cloud vs. Local
"Inference" is simply the act of running the model to get a response. As an LLM engineer, you must decide where that computation happens.
Cloud APIs (Managed)
When you use an API key for OpenAI or Anthropic, you are using Cloud Inference.
Pros: No hardware to maintain; highest possible intelligence.
Cons: Expensive at scale; dependency on a third party.
Local Inference (Self-Hosted)
Using tools like Ollama, you run the model on your laptop or a private server.
- The "Ollama" Revolution: It wraps complex C++ code into a simple API that lives at
localhost:11434. This allows developers to build apps that work offline and cost $0 in token fees.

Showcase: The "Multi-Model Insight Bridge"
To bridge the gap between theory and execution, I’ve developed the Insight Bridge: a Python-based diagnostic tool that benchmarks the "physics" and "economics" of AI. It pits Frontier models (GPT-5) against Local models (Llama 4 via Ollama) in a head-to-head sprint.
The Insight Bridge doesn't just look at the text; it audits the entire lifecycle of a prompt using four core metric pillars:
🕒 1. The Physics of Performance: Time & Traffic
We measure the raw speed and density of every request to determine which model wins the "race to the last token."
Latency ($ms$): Captured via
time.perf_counter(). We time the journey from the initial click to the final millisecond of the stream.Token Density: Calculated via
tiktokenorAutoTokenizer. For a lightweight estimate, we apply the "Rule of 4": $Length / 4$.Version Snapshots: We log the specific API string for Cloud (e.g.,
gpt-5-preview) and the exact manifest hash for Local Ollama instances.
💰 2. The Economic ROI: Efficiency & Cost
This is the "killer stat" for any enterprise-grade implementation—comparing the billable vs. the free.
Estimated Cost: A real-time lookup table multiplies token counts by current market rates (e.g., $$0.015$ per 1k tokens).
The Local Advantage: Local inference registers as $$0.00$, providing a direct visualization of the "Savings Gap" achieved by routing tasks to Llama.
Context Utilization: We calculate $\frac{Prompt Tokens}{Model Max Window} \times 100$ to identify if we are hitting the ceiling of the model's memory.
🛡️ 3. Governance & Safety: The Audit Trail
Every response undergoes a local scan on our FastAPI server to ensure data integrity and security.
PII Detection: We use Microsoft Presidio and Named Entity Recognition (NER) to flag Credit Cards, Emails, or SSNs.
Faithfulness & Safety: We calculate a Safety Score (checking for "jailbreaks") and a Faithfulness Score to ensure the model isn't hallucinating facts outside of the provided source context.
⚡ 4. Sustainability: Hardware & Energy
We measure the physical "weight" of AI by monitoring the local machine's vitals during generation.
GPU/Unified Memory: Queried via
pynvml(NVIDIA) orsystem_profiler(Mac M-Series) to track peak memory usage.Carbon Footprint: Using the CodeCarbon library, we calculate the energy draw: $(GPU Wattage + CPU Wattage) \times Time$. This allows us to assign a literal energy cost to every single prompt.
Ready to see the benchmarks?
Check out the code and benchmarks on my GitHub: Multi-Model Insight Bridge
Did you find this helpful?